|
I am a senior machine learning researcher at Apple, where I work on Computer Vision, Machine Learning, Robotics and AI for Science. I obtained my Master's degree in Computer Science from UT Austin, advised by Prof. Philipp Krähenbühl and Prof. Yuke Zhu. Prior to that, I obtained my Bachelor's degree in Computer Science and Applied Mathematics from UC Berkeley, where I'm fortunate to work with Prof. Trevor Darrell and Prof. Jitendra Malik. Email / Google Scholar / Twitter / LinkedIn / Github |

|
|
|
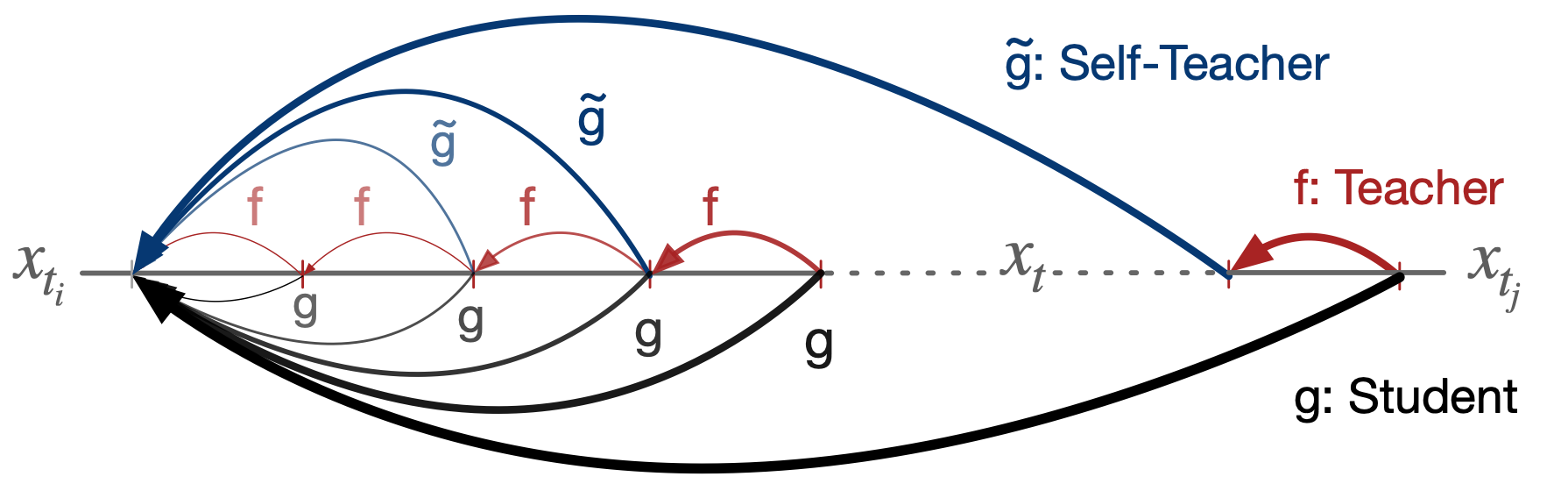 |
David Berthelot, Arnaud Autef, Jierui Lin, Dian Ang Yap, Shuangfei Zhai, Siyuan Hu, Daniel Zheng, Walter Talbott, Eric Gu arXiv Preprint, 2023 arXiv |
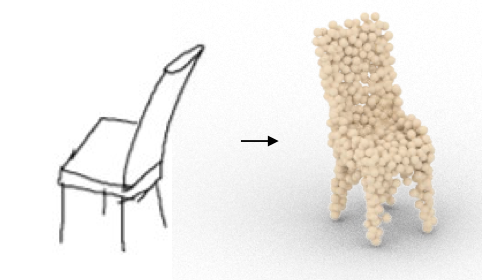 |
Jiayun Wang, Jierui Lin, Qian Yu, Runtao Liu, Yubei Chen, Stella X. Yu ECCV Workshop, 2022 arXiv / slides / code |
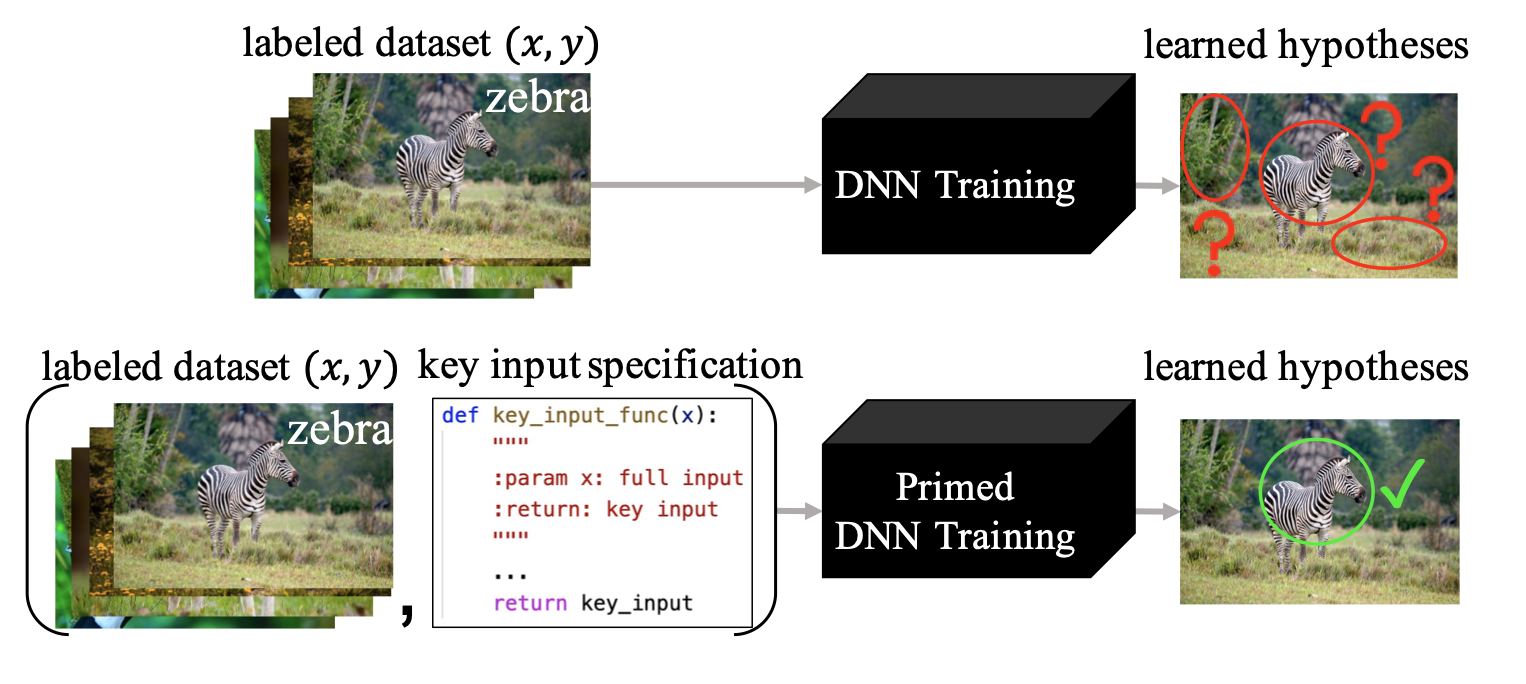 |
Chuan Wen, Jianing Qian, Jierui Lin, Jiaye Teng, Dinesh Jayaraman, Yang Gao ICML, 2022 arXiv / website / code |
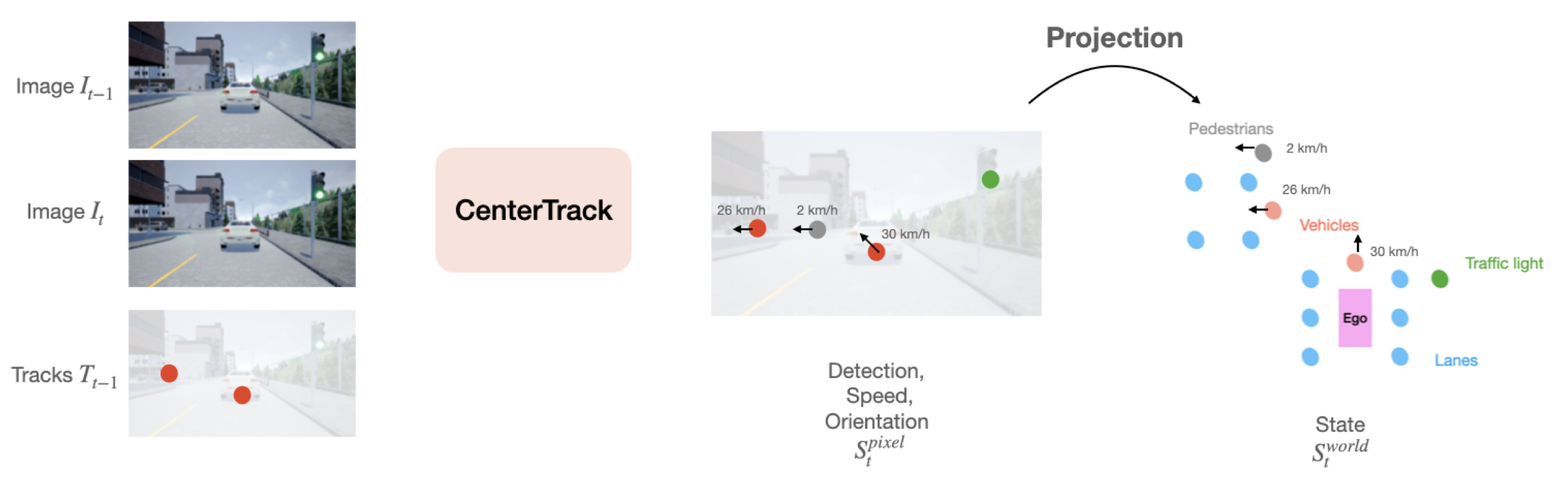 |
Jierui Lin Master's Thesis, 2022 arXiv |
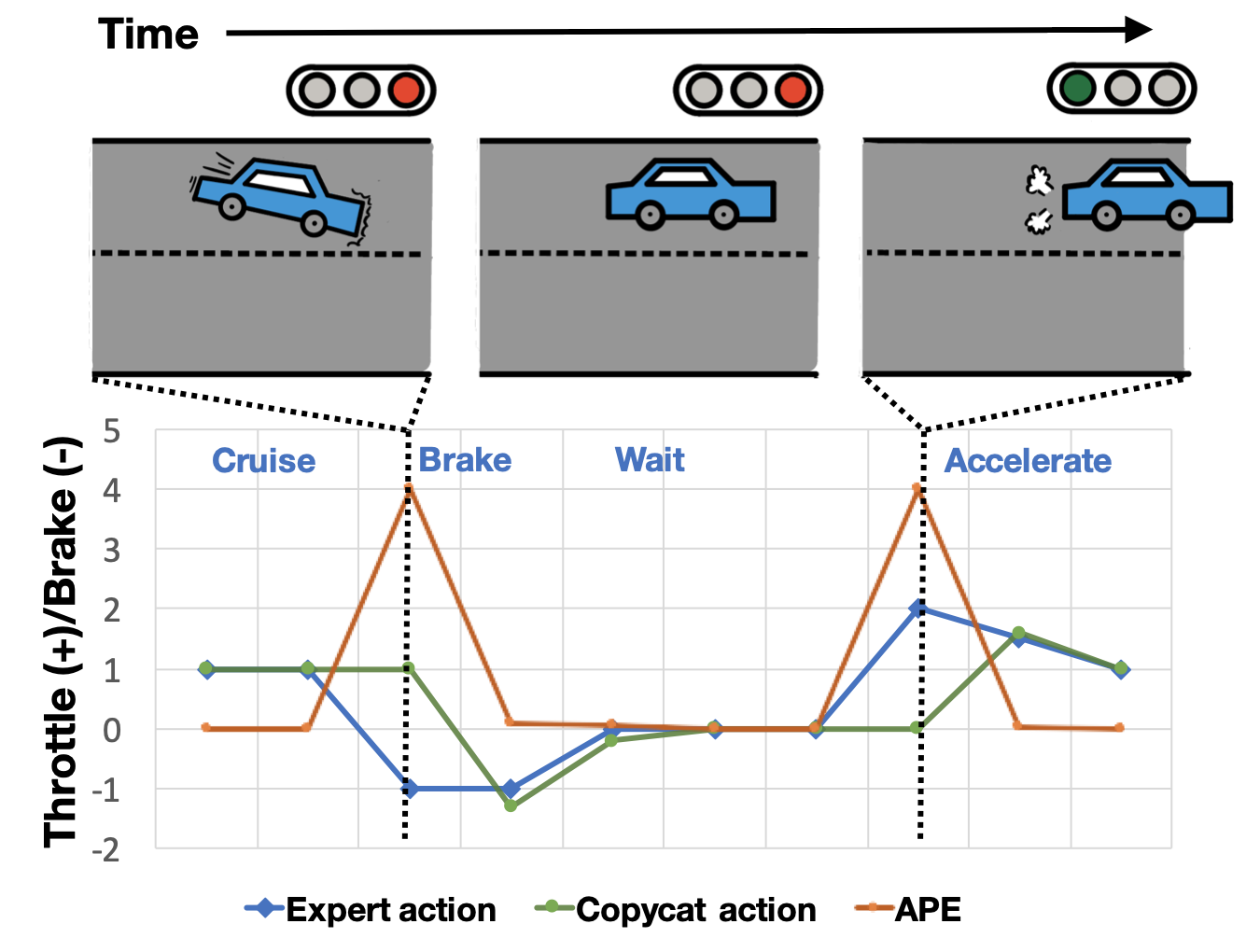 |
Chuan Wen*, Jierui Lin*, Jianing Qian, Yang Gao, Dinesh Jayaraman ICML, 2021 arXiv / website / code |
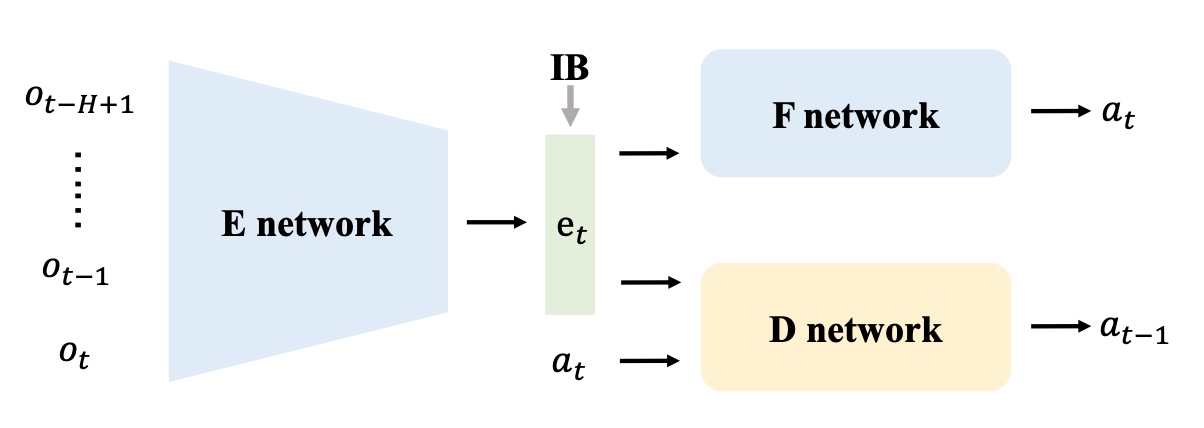 |
Chuan Wen*, Jierui Lin*, Trevor Darrell, Dinesh Jayaraman, Yang Gao NeurIPS, 2020 arXiv / website / code |
|
|
| Highest Honor in Applied Mathematics from UC Berkeley |
| Honor in Computer Science from UC Berkeley |
|
|
| Reviewer for NeurIPS, ICLR, ICML, CVPR, ICCV, ECCV, ACCV |
| Teaching Assistant for CS 170 (Algorithms), CS 188 (AI) at UC Berkeley, CS 342 (Neural Networks), CS 343 (AI) at UT Austin |
|
Design and source code from Jon Barron's website. |